며칠 전에 국무총리 산하의 제4기 공공데이터전략위원회 위원으로 위촉이 됐다.첫 회의에서 냈던 의견을 정리한다. 말하자면 ‘공공데이터의 조건’에 관한 얘기이자, ‘공공데이터의 실제 사용자’에 관한 글이다.
◆우리에게는 이미 수백 명의 오드리 탕이 있다
‘공공마스크앱’ 개발에 참여했던 경험으로부터 시작한다. 워낙 다급하게 진행됐던 일이다. 한국정보화진흥원(NIA)이 PM을 맡았다. NIA가 가장 먼저 한 일은 시빅 해커들을 불러모으는 것이었다. “어떻게 하면 좋겠는가?” 의견을 묻고 경청했다.
“수백만 명이 동시에 앱을 열텐데 거기서 쏟아지는 트래픽은 심평원(건강보험심사평가원)에서 절대로 감당을 하지 못할거다, API서버 등 트래픽을 직접 받는 부분은 모두 네이버나 KT 등 민간클라우드로 올려야 한다”, “심평원에서 어떤 데이터를 줄지 모르지만, 데이터 포맷을 먼저 알려달라, 그러면 데이터 없이도 앱을 미리 만들어 놓을 수 있다”, “반드시 베타서비스라는 것을 명시해라, 급히 연 다음 계속 업데이트를 해야 하는데, 자칫 기대수준 관리를 못하면 좋은 일을 하고도 큰 비난을 부르게 된다” 등 여러 얘기들이 나왔다. NIA는 즉각 이를 수용했다. 그리고 사흘만에 시빅해커들이 만든 앱이 속속 공개됐다. 전설같은 순간이었다. 자신들의 엔지니어링 기술로 동료 시민들을 도울 수 있어 기뻐하던 개발자들을 지켜본 것은 근래 가장 즐거운 경험이었다.
말하고 싶은 것은 우리나라에도 수백 명의 오드리 탕이 있다는 것이다. 공공데이터전략위원회에는 더 많은 시빅해커들이 초대를 받아야 한다. 이번 4기에는 권혜진 투명사회를 위한 정보공개센터 공동대표 한 분 정도가 시빅 해커라고 할만하다. 더 많은 젊은 해커들이 전략을 만들 때부터 참가해야 한다. 실제로 공공데이터를 사용하는 것은 엔지니어들이기 때문이다. 기업이나 연구기관에서 공공데이터를 쓴다고 해도 그걸 다루는 것이 엔지니어라는 건 바뀌지 않는다. 실제로 쓸 사람들의 의견이 반영이 돼야 한다.자동차를 내다 팔고 싶으면 자동차를 살 사람들을 대상으로 시장 조사를 하는게 당연하듯, 공공데이터를 개방한다면 그것을 쓸 엔지니어들에게 처음부터 의견을 물어야 한다.
◆기계가 읽을 수 있어야 한다
그런데 엔지니어들보다 더 중요한 사용자가 있다. Machine, 즉 기계다. 엔지니어가 코딩을 해서 데이터를 수집할 때 그것을 처리하는 것은 컴퓨터다. 그래서 공공데이터를 공개할 때 첫번째 조건은 ‘Machine Readable’, 기계가 읽을 수 있어야 한다는 것이다. 우리나라는 공공데이터의 개방에 있어 OECD에서 가장 앞선다. 3년 연속 1위를 차지하고 있다. 아쉬운 부분이 있다면, 개방된 데이터들의 일부는 기계가 읽을 수 없다는 것이다. 사실은 공개된게 아니라는 뜻이다. 크게 3개의 영역이 있다.
하나씩 보자.
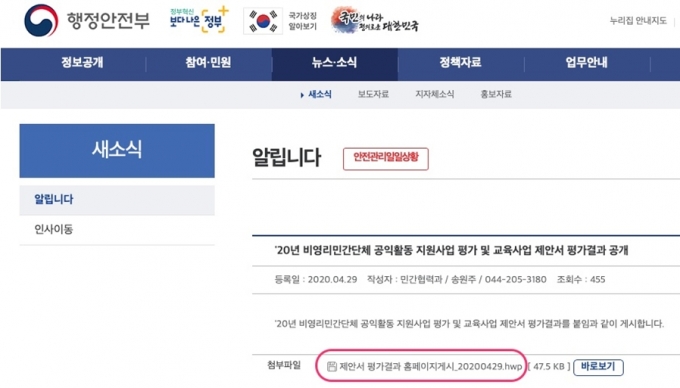
개방형문서형식(Open Document Format for Office Applications, ODF)이라는 게 있다.위키백과의 설명은 이러하다.
“스프레드시트, 차트, 프레젠테이션, 데이터베이스, 워드 프로세서를 비롯한 사무용 전자 문서를 위한 파일 형식이다.이 형식은 원래 오픈오피스에서 만들고 구현한 XML 파일 형식을 바탕으로, OASIS(Organization for the Advancement of Structured Information Standards) 컨소시엄이 표준화하였다. 2006년에는 국제 표준화 기구 및 국제 전기 표준 회의의 인증을 받아 ISO/IEC 26300:2006으로 발표되었다. “이 포맷을 쓰면 기계가 쉽게 자동으로 처리를 할 수가 있다. 데이터가 된다는 뜻이다. 기계가 읽을 수 있다는 것은 ‘기계가 자동으로 처리를 할 수 있다’는 뜻이다. 수백만 개의 정부 발행문서들을 사람이 일일이 수작업으로 처리하기는 불가능하다. 다시 말해 버려지는 문서라는 뜻이다. 아래아한글은 표준포맷이 아니어서 기계가 자동으로 처리를 할 수가 없다. ‘데이터는 새로운 석유다’, ‘디지털경제는 데이터경제다’를 주창하는 정부에서 지금 이 순간에도 기계가 읽을 수 없는 문서들을 끊임없이 홈페이지에 ‘공개’하고 있는 것은 진심으로 안타까운 일이다.
두번째는 숫자로 가득한 PDF 파일이다.
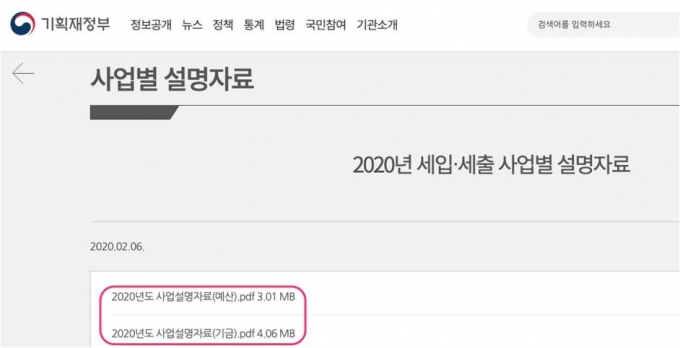
세 번째는 웹페이지들이다.

익산의 천만송이국화축제 홈페이지다. 다른 많은 지역축제와 마찬가지로 전체 일정표와 주차안내가 올라와 있다. 하지만 짐작하듯 이것도 사람이 개입해야 데이터가 된다. 포맷이 제각각이기 때문이다. ‘구조화된 데이터’(Structured data) 포맷을 쓰면 기계가 웹페이지를 자동으로 처리할 수 있다. 웹사이트자체가 공개 데이터로 변모할 수 있다는 것이다.이렇게 하면 전국 지자체의 축제 일정과 주차장 위치가 단번에 하나의 데이터로 만들어질 수 있다. 기계가 자동으로 처리할 수 있기 때문이다.
이쪽에서 가장 유명한 포맷은 Schema.org다. 구글과 MS, 야후가 함께 손잡고 2011년 시작했다. 표준 용어와 메타데이터를 정하고, 이것을 웹페이지들이 함께 쓰게 함으로써 기계가 자동으로 웹페이지의 데이터들을 처리할 수 있게 하자는 시도다. 구글 등은 구조화된 데이터용 테스트 도구 및 URL 검사 도구를 제공한다. 우리도 이 포맷에 준해 우리 사정에 맞는 표준 용어와 메타데이터들을 더하면 정부와 공공기관의 웹사이트들을 거대한 공공데이터셋으로 만들 수 있다. 디지털뉴딜정책의 하나로서도 아주 해봄직한 일이 될 것이다.네이버와 다음과 같은 국내 검색서비스들이 재능을 보탠다면 더욱 훌륭하겠다.
◆지침만으로는 안된다
수년 전의 일이다. 지금은 많이 다를 것이다. 하나의 예시로 소개하는 것이다. 관광공사에는 반짝이는 데이터들이 아주 많다. 당연히 여행스타트업이라든가 포털들에서 가져다 쓰고 싶어한다. 그런데 담당자가 난색을 표하는 것이었다. 상반기 전산 예산의 절반을 다운로드 트래픽 비용에다 써버려 위에서 눈치가 이만저만이 아니라는 것이다. 일을 열심히 잘한 덕분에 말하자면 ‘찍혔다’는 것이다. 공공데이터와 관련해서는 담당자와 기관의 평가점수에 반영할 뿐더러, 공공데이터 개발뿐 아니라 운영에도 예산이 함께 지원이 돼야 한다. 그렇지 않으면 일을 열심히 할 유인이 없다. 눈치없이 열심히 한다고 핀잔을 먹지 않으면 다행이지. 데이터는 공개하는 것으로 끝나는게 아니라 제때 업데이트가 돼야 한다. 이것은 잘 안보이는 일이다. 이런 일들이 평가와 예산에 반영이 돼야 실제로 쓸 수 있는 공공데이터가 된다.
◆통계가 아니라 로데이터(Raw data)
연구목적으로 데이터를 쓸 때는 누군가 가공해 놓은 통계가 아니라 원 데이터가 필요하다. 내가 ‘킹덤’을 보고 싶은데 선배가 “걱정마, 내가 스토리 다 얘기해줄게”라고 하면 그게 무슨 도움이 되겠는가? 통계는 줄거리를 얘기해주는 선배와 같다.
모든 로 데이터를 다 공개하기는 현실적으로 어려울 것이다. (1)자주 요청을 받는 데이터는 로 데이터로 제공을 한다, (2)한번이라도 제공한 적이 있는 로 데이터는 특별한 사정이 없는 한 전체 공개한다, (3)로 데이터를 제공받아 정제해서 연구에 사용한 기관/사람은 정제한 데이터를 전체 공개로 다시 제공해야 한다 정도를 원칙으로 하면 어떨까 생각한다.
데이터는 새로운 석유다, 기계가 읽을 수만 있다면! 세계 최고의 공공데이터 공개국에서 세계 최고의 ‘기계가 읽을 수 있는 데이터 보유국’으로 한 단계 더 진화하자. 디지털 뉴딜은 이것을 하기에 다시 없이 좋은 계기다.
박태웅 한빛미디어 이사회 의장

--comment--
첫 번째 댓글을 작성해 보세요.
댓글 바로가기